






以下是引用本文的既定格式:
Rocha, j.c., l.b. Luvuno, j.t. Rieb, e.t. h Crockett, K. Malmborg, M. Schoon和G. D. Peterson, 2022。Panarchy:边界概念的涟漪。生态与社会27(3):21。摘要
社会生态系统如何随时间变化?2002年,C. S. Holling和他的同事提出了panarchy的概念,将社会-生态系统描述为一组相互作用的适应性周期,每个周期都是由多尺度上的新奇性和效率之间的动态紧张关系产生的。panarchy最初是作为一种概念框架和一组隐喻引入的,已经获得了许多学科学者的关注,它的思想继续激励着概念的进一步发展。在这个概念被引入近20年后,我们回顾了它是如何通过定性方法和机器学习的结合来使用、测试、扩展和修改的。采用文献分析方法对科学文献(N = 42)的泛结构特征进行编码,对2177篇文献进行定性分析,并对其进行主题建模。我们发现,适应周期是panarchy最受关注的特征。挑战仍然存在于经验基础的隐喻,但最近的理论和实证工作提供了一些未来研究的途径。介绍
大约20年前,Gunderson和Holling在《Panarchy: Understanding changes in Human and Natural Systems》(Gunderson and Holling 2002)一书中提出了一个综合的视角,阐述了一群与弹性联盟相关的社会-生态研究者如何理解社会-生态系统的变化。全面性的概念是这本有影响力的书的一个关键焦点。在20世纪90年代末和21世纪初,弹性联盟是一个多产、创新和高度协作的跨学科科学家团队,他们专注于解决社会生态问题。他们通过结合来自社会和自然科学、艺术和人文科学的见解,以及连接理论和实践(帕克和哈克特2012)来做到这一点。Panarchy仍然是一个边界对象,它激发了研究主题,使合作成为可能,并培养了新的科学框架(Parker and Hackett 2012)。提出的想法已应用于实地研究、考古学、数学模型、参与性工作和情景开发(Gunderson等,2022)。Panarchy启发了弹性评估并指导决策。在本文中,我们通过研究这些概念和隐喻是如何在学术文献中得到进一步发展的来致敬这本书。我们还记录了对这些概念的批评,并确定了关键的研究前沿。
panarchy的概念建立在Holling的adaptive cycle (Holling 1986)的基础上,将这个概念扩展到空间和时间尺度。Panarchy提出用相互作用的自适应循环来概念化系统是有用的。适应性循环是霍林根据他工作和研究管理生态系统的经验首次提出的想法(霍林1986年)。它是一个概念上的工具,把注意力集中在与增长和养护相比被忽视的破坏和重组过程上。
一个自适应的循环在长时间的系统聚集、连接和积累和短时间的中断和重组之间交替。自适应周期分为四个阶段,分为两个主要的循环(图1)。r)、保护(K), (Ω),以及重组(α),后者以创造性破坏事件为特征(图1)。第一个回路,通常被称为前回路,来自r来K,是成长和积累的缓慢增量阶段。第二个回路,称为回回路,从Ω来α,是重组导致更新的快速阶段。进入回环的系统可以保持类似的形式,也可以过渡到具有新的边界和关键部件的新型系统(Holling et al. 2002)。弹性研究人员提出,在许多不同类型的复杂系统中,对组织和效率的需求与对新颖性和多样性的需求之间的紧张关系驱动了自适应循环动力学(Holling et al. 2002)。
”Panarchy不是一个关于它是什么的理论,而是一个关于可能是什么的隐喻”(Gunderson and Holling 2002:32)。它不是一个预测工具,而是旨在了解适应性变化。适应性循环被认为存在于一个三维空间中,由三个属性定义:潜力、连通性和弹性(Gunderson和Holling 2002)。潜力是指系统可获得的资本,例如森林捕获的营养物质和碳,或人力资本,即为运行经济而积累的技能和知识。连通性是系统结构的代表;它是元素之间相互作用和力量的网络。弹性是任何系统在经历变化时吸收干扰和重组的能力,以保持本质上相同的身份,这是由其功能、结构和反馈决定的(Folke 2016)。
Panarchy假设系统是在跨空间和时间的嵌套层次结构中组织的,其中层次结构的每一层都是子系统,可以处于适应周期的不同阶段。这些阶段受到经济学和生态学中使用的数学模型的启发,但广泛地描述了人口、生态社区、市场或政治组织常见的增长、崩溃和恢复模式。然而,层次结构中的每个子系统可以处于适应周期的不同阶段,这些子系统可以通过跨尺度的相互作用特别地相互影响,或者称为反抗,在较小、更快的子系统中发布可以触发更大、更慢的子系统中的发布,或者称为记忆,在其中较大、较慢的子系统的结构塑造较小、更快子系统的重组动态(Gunderson和Holling 2002)。
由潜力、连通性和弹性定义的三维空间有一些角落,有可能使适应性循环脱轨的吸引物:贫困和僵化陷阱(Gunderson和Holling, 2002)。在Panarchy中,贫困陷阱被描述为潜在能力、连通性和恢复力较低的适应性不良状态。贫困陷阱是一系列强化贫困状态的反馈机制(Allison and Hobbs 2004, Bowles et al. 2006, Maru et al. 2012),限制了系统创新和增加潜力的能力。另一个角落,即潜力、连接性和弹性都很高的地方,是另一个被称为刚性陷阱的不适应空间。在那个角落,几乎没有实验和创新的空间。例如,生态恢复力已被人工过程广泛取代的系统,以维持系统,如堤防、防洪屏障或对害虫的化学控制(Holling和Meffe 1996)。
Panarchy为解释环境问题提供了一个丰富的概念框架。尽管受到几种数学结构(例如,循环、陷阱、比例定律)的启发,邀请来自多个学科背景、本体论和认识论的学者围绕研究问题和应用问题进行合作是足够普遍的。因此,它是有用的边界对象,可以使用经验或隐喻。这本书展示了一系列的案例研究,地理学家、经济学家、政治科学家和生态学家已经证明了该框架对他们研究领域的效用。
科学理论是回答这个问题的知识体系,为什么?这个答案意味着因果推理。因此,无论如何,一个理论应该提供一系列可测试的预期,以帮助区分它是对现实的良好解释时的情况,与它不尽如人意时的情况。科学的实践意味着避免确认偏见和检验,当解释是对现实的有效表征。在这篇论文中,我们探索了panarchy的概念框架是如何在过去的二十年中被应用、发展和测试的。panarchy要想在可持续发展科学中成为一个有用的理论,它需要能够在不同的背景下解释社会生态系统中的现象,以一种可测试的方式,并经受住这些测试的严格考验。在这里,我们回顾了过去二十年的学术文献,以追溯Panarchy中提出的想法是如何演变的。最后,我们提出了未来工作的研究前沿。
方法
为了回答这些问题,我们将基于主题建模(Griffiths and Steyvers 2004, Blei 2012)的自动文献综述与人类编码的文档分析(Bryman 2008)结合起来。我们首先描述数据管理以及如何在主题模型中使用它。然后我们引入定性方法。
数据
我们使用Web of Science、Scopus和GoogleScholar来调查使用或引用了追溯到panarchy (Gunderson和Holling, 2002)的著作的学术文献。我们从Scopus数据库中提取了与搜索匹配的完整记录”panarchy”或”自适应周期”(N = 595),即搜索”panarchy”或”自适应周期”而且”弹性”(N = 278)。数据与所有论文(N = 1923年)结合在一起,这些论文引用了将这本书介绍给学术界的第一篇论文(霍林2001年)。缺少摘要的记录被删除(N = 191),缺少年份的记录被设置为2020年,因为它们是计划在2020年或2021年晚些时候发布的数字对象标识符(DOIs)接受手稿。我们最终的样品是2177个文件。
为了准备用于主题建模的数据,我们构建了一个文档术语矩阵,其中文档在行中(N = 2177),单词在列中(N = 12,744)。在这里,我们对文档的分析单元是检索到的摘要,矩阵包含每个摘要中每个单词出现的次数。我们去掉了停止词(例如:”的,””一个”)和矩阵中的数字,以及在我们的数据中过多出现的词汇列表,这些词汇在科学文献中很常见,但与论文的主题无关(例如,”纸,””研究中,””目的”).停止词词典有1149个条目,由不同的研究小组策划,并可在R语言包tm和tidytext下访问(Feinerer et al. 2008, Feinerer和Hornik 2020, Hornik 2020, Grün和Hornik 2021, Robinson和Silge 2021),例如,通过tidytext::stop_words。数据也使用可用的散列引理数据集进行了词素化<一个href="https://www.lexiconista.com" target="_blank" rel="noopener">https://www.lexiconista.com.词根化是将单词简化为词根词根的过程,例如:”教学”而且”教”是lemmatized”教书。”
主题模型
主题模型是一种无监督的统计技术,用于将数据语料库(通常是文本,但不一定是文本)降维为主题(Blei 2012)。在这里,主题是一个潜在变量,它对在同一文档中同时出现的概率高的单词进行排名。文档又可以通过特定主题集的概率分布来描述。因为它们是(后验)概率,任何给定主题的所有单词的概率之和应该是1,任何给定文档的所有主题的概率之和也应该是1。迭代过程或算法允许模型学习最能解释主题的单词的排名,以及最能解释文档的主题的排名。
这种机器学习方法的基础统计技术被称为潜在狄利克雷分配(LDA;Blei et al. 2003)。它根据文本数据中单词的分布,假设多元连续分布,即狄利克雷分布,为潜在变量(即主题)分配概率。我们比较了三种LDA算法:相关主题模型(CTM)、变分期望最大化(VEM)和吉布斯抽样(Gibbs sampling),通过对它们的对数似然估计、熵和困惑度评估它们的性能(Grün和Hornik 2011)。熵是一个系统有序或无序的量度。在主题模型上下文中,它衡量主题分布分布的平均程度。Perplexity度量的是预测单个单词的不确定性,所以如果模型表现与random相同,Perplexity将近似于词汇量的大小(N = 12744个单词)。这些性能指标使我们能够选择最适合数据的算法,适合的主题的最佳数量,以及如何避免过拟合。
文档分析
我们通过对论文样本(N = 42)编码一组额外的分类变量来补充我们的无监督方法与文献分析(Bryman 2008)。阅读的论文是用于主题建模的语料库的一部分。我们阅读论文,避免选择高引用的论文、特定的期刊、旧的论文或特定的学科或方法。
在阅读Panarchy的基础上,我们首先开发了一系列的分类变量,捕捉了科学框架的主要组成部分。在2019年的恢复力联盟科学会议上,这些变量得到了展示和反馈。我们使用变量来注释定性方面,如使用适应周期,识别其阶段,以及该论文是概念性的,建模的,或实证研究。实证时,我们记录了案例研究的时间和空间尺度。我们还区分了经验案例和经验构念。经验性案例是指当一项研究试图检验一个由panarchy提出的想法或命题,例如,跨尺度的相互作用,或回环比前环更快。经验建构是指将全面性作为解释案例研究的灵感,通常带有历史成分,例如确定适应周期的各个阶段。但它并没有找到支持或反对泛主体前置的证据。也就是说,没有一种机制可以避免确认偏误。
我们还确定了panarchy的哪些方面在论文中被使用的最多,例如,是否有一个跨尺度互动的重点,或贫穷和刚性陷阱。我们使用文本注释来捕捉潜在的批评以及所使用的方法。我们对论文进行了初步的界定和编码,通过迭代过程,我们跟踪语料库审查的潜在场,或者只是从语料库中缺失的潜在场。我们对论文进行编码,直到达到概念饱和,也就是说,额外的论文不能证明额外的类别。代码本可以在<一个href="https://doi.org/10.6084/m9.figshare.13490919" target="_blank" rel="noopener">https://doi.org/10.6084/m9.figshare.13490919.
结果
2002年出版的《Panarchy》在2022年3月被谷歌Scholar引用了8600多次。将这本书介绍给科学界的科学论文(Holling 2001)在撰写本文时已经收到了科学网(Web of Science)的1853次引用和Scopus的2197次引用。大约一半的引用来自环境(28%)和社会科学(22%)。计算机科学(2.1%)和人文艺术(2.6%)的比例最低。
主题建模使用Gibbs sampling。在我们对其他LDA算法的比较中,Gibbs sampling提供了对数据的最佳拟合(图2)。根据经验,理想的方法应该在最小化困惑的同时最大化熵和对数似然估计(Grün和Hornik 2011)。与其他选择相比,吉布斯抽样最大化了我们的数据的熵和似然。其次是变分期望最大化算法α不是常数。α是一个超参数,对主题分布的均匀性进行加权。一个较低的α默认值表示文档可以用更少的主题描述,或者它的分布非常不均匀。事实上,我们观察到,从5个主题增加到100个主题确实增加了熵,但以减少熵为代价α,这意味着尽管主题的数量更多,但文档的主要内容仍然由其中的一些主题捕获。对数可能性最大化在25到50个话题左右停止。因此,我们将其余的分析限制为25个主题。
主题是一组单词,根据它们代表文档底层内容的概率进行排序(图3)。例如,单词”弹性,””自适应,”或”能力”很有可能捕捉到主题14的内容。我们时间序列的早期(2001-2003)的论文内容丰富,主要是主题14关于恢复力,9关于资源管理,23关于跨尺度互动。在时间序列接近尾声时,关于城市系统的主题7和关于当地社区和知识的主题25在每年(2019-2020年)的内容中所占比例上升到9%。作为比较,如果所有的主题在内容中相同的表示,它们在语料库中的占比为4%(图3中B的灰线)。为了再现性的目的,出现的主题缺少名称。而在这里,例如,我们将主题7作为城市主题,如果研究人员复制分析,他将发现相同的单词列表和概率分布列在一个不同数字的主题下。这是因为主题的标签是随机的,我们敦促读者不要过度解读发现的词模式。
尽管有波动,但随着时间的推移,大多数话题表现出相对稳定的兴趣水平(图3、图4)。我们没有观察到强烈的趋势,但一些话题获得了少量的关注。例如,关于可持续性的主题11和关于生态系统服务的主题15在不同时期出现一致。相比之下,近年来,创新(主题18)、城市基础设施(主题7)和地方社区(主题13)的研究受到了关注。主题6是一个异类,一些论文在与网络基础设施和性能相关的内容上排名很高,可能来自工程学科。它是唯一一个在一系列论文中与其他论文明显不同的主题,并且随着时间的推移呈现出减少的趋势。
人类编码的文档分析显示,在文献中,panarchy最常见的特征是自适应周期(81%,N = 42中的34),其次是跨尺度交互(图5)。在我们的样本中,贫穷和刚性陷阱是较少研究的特征(分别为14%和19%),即使考虑到略有不同的术语,如”锁定。”所分析的论文中约有一半(52.4%或22/42)为概念性论文,许多论文没有明确的方法或明确的研究问题。大约一半(20/42)的论文使用panarchy作为比喻。在我们的样本中,约有40%的论文(17/42)更进一步,将panarchy作为一个经验结构,例如,试图识别适应周期的各个阶段(26/42)。在22个经验案例中,有6个是以世纪为时间尺度,7个以十年为时间尺度,6个以年为时间尺度,1个以周为时间尺度。在空间上,4次是城市规模,17次是区域规模,1次是全国规模。实证论文主要使用定性方法(17),主要是回顾性的历史回顾。
大多数被审查的论文(81%,N = 42篇中的34篇)通过科学方法或类比或框架来确定适应性循环。适应性周期的识别已经在广泛的学科和研究问题中得到了应用,从考古学和人类学的时期划分(Redman和Kinzig 2003),瑞典森林相关部门之间的系统相互作用(Moen和Keskitalo 2010),欧洲的金融危机(Castell和Schrenk 2020),到中国的交通堵塞(Zeng等人2020)。适应性周期已被用作一种模型,以构建有关参与适应性管理的丰富经验信息,并基于该分析,制定了更灵活的利益相关者参与建议(Stringer等,2006)。适应性循环还被用于提供各种特定社会-生态系统历史的更机械的描述,包括加拉帕戈斯群岛(González et al. 2008),西澳大利亚农业地区(Allison and Hobbs 2004),中国西南部的洱海流域(Dearing 2008),以及英国的剑桥和斯旺西(Simmie and Martin 2010)。适应性循环也被用来描述更一般的社会和生态过程,如湖泊富营养化(Carpenter等,2001)和区域产业集群的发展(Martin和Sunley 2011)。
最近对适应周期的实证检验使用了创新类型的数据和方法。例如,基于熵的信息传递方法被建议用于近似系统的相关组件和适应周期展开轴线的经验代理:潜力、连接性和弹性(Castell和Schrenk 2020)。结合大数据的渗透方法已被证明对检验城市系统的制度变迁假说有用,这一想法最初是在Panarchy (Gunderson和Holling 2002)中提出的,并推导出适应周期出现的时间和空间尺度(Zeng et al. 2020)。
讨论
我们审查了panarchy的概念框架是如何发展和测试在过去的二十年。我们使用主题建模来分析大量的论文,并对一组多主体论文的选择进行重点审查。我们发现,泛结构已经被用作跨各种各样的主题的解释工具,但是在实质性地操作或测试泛结构方面很少有努力。
可持续发展科学的定义是它所解决的问题,而不是它所使用的学科(Folke 2016)。本文的目标是探索panarchy中提出的想法是如何演变的,它们被应用到什么类型的问题,并发现有用的,最后,什么关键的研究前沿仍然存在。我们的主题建模结果有助于确定社区正在解决的一些问题,以及它们如何随着时间的推移发生变化。其中一些问题包括气候变化(主题24)、城市发展和灾害响应(7)beplay竞技、保护和景观管理权衡(5)、自然资源管理(9)、粮食生产(3)、政策工具和计划(16)、社区管理(13)或知识和当地社会实践(25)。我们还观察了与研究社会-生态系统的方法或方法密切相关的主题,如建模(19,21)、网络(6)或生态系统服务(15)。主题建模可以用于进一步调查特定的学术团体,确定特定主题中的关键里程碑论文,或确定关键合作者和专家的网络。
本文旨在研究panarchy相关概念的使用及其自该书出版以来的演变(Gunderson and Holling 2002)。系统的文献综述通常局限于几十到数百篇文献的一个有限子集,基于项目的时间框架的可读性。定性分析为综述的论文提供了丰富的见解,但其得出一般性结论的能力受到样本量的限制。在我们的分析中,定性的见解可能偏向于与我们的研究兴趣一致的非随机选择的论文,或高引用的评论论文。主题建模使我们能够补充分析,并包括所有被主要科学数据库索引的论文。它具有可重现性和减少样本偏差的优势,但对所使用的panarchy维度、方法或批评提供了有限的见解。通过结合各种方法,就像我们在本文中所做的那样,我们相信文献综述可以变得更加强大。
但是,我们对方法的选择确实有一些局限性。我们不能直接比较这两种方法,因为它们没有一个共同的分类轴,我们可以用这个分类轴在方法之间进行转换。主题建模有助于理解与什么主题相关的主题,例如,单词集、泛结构;我们的文档分析有助于深入理解人们如何解释和使用这些概念。这些主题为我们提供了广泛而浅显的概述,而文件分析提供了对特定工作的深刻见解,但有限的概括。我们的方法还忽略了社会科学研究的丰富领域(如人类学),这些领域通常发表在书籍和书籍章节中,而这些内容没有被科学搜索引擎存档。最后,定性编码的迭代归纳方法可能会让我们对我们最初与弹性联盟共享的预定义类别之外的文献有不同的见解。
未来对panarchy或其他概念的研究,可以从我们的经验中受益。Panarchy是概念的集合,其中一些比其他的更常用和发展,比如适应性循环。未来的评论将受益于灰色文献,如论文、书籍、非政府组织报告、政府机构报告或非英语文献。这将让我们看到panarchy概念在更多应用环境中的使用,如管理和决策。全文而不是摘要的使用也可以为自动化分析提供额外的见解,例如,归因社会-生态系统的制度变化对生态系统服务的影响(Rocha和Wikström 2015)。虽然数据库正在改进,但全文分析只适用于开放获取的期刊,而且文本分析很难跨越多种语言。数据库正在扩大图书和报告的覆盖范围,这表明我们的方法可能在未来能够访问更广泛的文献。
我们对panarchy论文的回顾(N = 42)揭示了高水平的概念化,但缺乏理论发展或测试。概念性框架,如panarchy,作为边界对象具有重要的作用,使跨学科对话成为可能。panarchy在这个角色中的作用是通过它如何被用来解决从人类学到工程等领域的各种问题来揭示的。我们回顾的许多论文使用适应周期来解释过去的事件,但没有进行测量或观察来测试当前或潜在未来轨迹中的适应周期,也没有测试panarchy的其他特征,如贫穷或刚性陷阱,或反抗和记住跨尺度的相互作用。目前仍缺乏可检验的机械理论来解释panarchy的动力学,因此,也缺乏在现实社会生态系统中测量或观察它的方法。
考虑到我们的论文样本(N = 42),高水平的概念化但缺乏理论测试是主要的限制之一。一种理论之所以是一种科学理论,是因为多种科学方法(如实证主义、建构主义)应该有避免确认偏差的机制,允许出现其他解释,并确定理论可能失败的情况(Hansson 2017)。我们阅读的许多论文证实了panarchy提出的预期,但没有挑战,尽管最近的一些作品确实伪造了一些提出的想法,例如,回环比前环更快(Castell和Schrenk 2020)。我们相信,需要做更多的工作来更好地理解当全面性发挥作用时的情况,以及当全面性发挥不足时的情况:换句话说,将科学框架细化为科学理论。
对过度概念化的批评并不只存在于涉及全方位思想的文学作品中。我们所说的过度概念化指的是科学术语的问题,不同的社区使用略微不同的词汇来指代同一现象,减少了从一个学科学到的教训渗透到另一个学科的机会。一个来自panarchy的例子是对一些观点的支持,比如来自经济学的创造性破坏,或者来自生态学的中间干扰理论。后者在生态学文献中被揭穿了(Fox 2013)。最近一篇关于可持续发展科学的综述描绘了该学科在过去几十年里发展的不同思想流派(Clark and Harley 2020),并得出了类似的结论:开发了太多的概念框架,但很少有实证尝试根据数据检验框架,并伪造假设。综述还强调了测量和观测的问题(Clark and Harley 2020)。在panarchy的背景下,最近的研究开发了一种基于信息论的方法,能够识别适应性周期(Castell和Schrenk 2020)。作者在欧洲金融危机和草地生态系统中确定了适应循环的阶段,但未能找到最初在泛结构中提出的前向和后向循环速度差异的支持。同样的观点在城市交通研究中也缺乏支持(Zeng et al. 2020)。
在我们的定性分析中受到较少关注的panarchy维度包括创造性破坏、刚性和贫困陷阱。这可能至少部分是因为我们的数据范围:引用了panarchy或Holling论文的论文(Holling 2001, Gunderson和Holling 2002),以及相对较小的样本量(N = 42)。诸如创造性破坏和贫穷陷阱之类的概念先于panarchy,因此在panarchy的思维流之外已经被理论化和经验化。例如,贫困陷阱的理论可以追溯到20世纪50年代的经济学,并得到了理论发展(Bowles et al. 2006)和实证基础(Banerjee and Duflo 2012, Banerjee et al. 2015),这使得研究人员和政府能够区分什么样的干预措施可能减少贫困。考虑到研究人员对贫困陷阱所做的工作,我们认为,提出和评估可能产生适应性周期的潜在机制,它们的跨尺度相互作用(例如,记忆和反抗),或复杂系统的等级、嵌套性质如何增强或侵蚀社会-生态系统的恢复力,将是富有成效的。
结论
本文探讨了panarchy的概念框架在过去20年里是如何被使用、发展和测试的。尽管有越来越多的文献,但似乎没有一个主题能主导使用泛主体概念的论文。适应性周期是应用最广泛的概念,它被用于解释历史,从自然资源管理的动态和城市发展,到跨越千年的考古学和人类学研究。跨尺度动力学、结构和陷阱较少受到关注。运作化panarchy理论仍然是一个挑战。如何测量和预测系统行为的方式是有用的panarchy的概念仍然是一个开放的问题。有效地解决这些问题将包括开发工具来回答有关关联的社会-生态系统的恢复力动态的关键问题。例如,当前全球粮食体系的变化如何改变其恢复力、连通性和潜力?我们如何确定一个社会-生态系统是否进入了一个不同的适应周期阶段?是什么样的记忆或反抗动力塑造了斯德哥尔摩或Bogotà目前的食物系统? Although our survey of the literature identified a few promising pathways, developing ways to operationalize theories that explain the dynamics of resilience is vitally needed to confront the challenges of creating a sustainable, just world.
对本文的回应
欢迎对本文作出回应。如果被接受发表,您的回复将被超链接到文章。<一个href="//www.dpl-cld.com/responses.php?articleid=13374&mode=add">要提交响应,请点击此链接.<一个href="//www.dpl-cld.com/responses.php?articleid=13374">要阅读已经接受的回复,请点击此链接.作者的贡献
j.c.r.、l.l.r.、j.r.、e.t.h.c.、m.s.和g.p.在2019年的韧性联盟会议上提出了最初的想法。J. C. R. L. L. J. R. E. T. C.和K. M.阅读和编码科学文章。J. C. R.在团队的支持下开发了代码和主题建模分析。所有作者都写了这篇论文。
致谢
j.c.r.获得Formas研究基金(942-2015-731)、斯德哥尔摩恢复力中心和斯德哥尔摩大学的资助。我们感谢韧性联盟的反馈和对我们进行这个项目的鼓励。国内生产总值感谢拉斯穆森基金会的支持。
数据可用性
复制分析的所有数据和代码都可以在<一个href="https://github.com/juanrocha/panarchy" target="_blank" rel="noopener">https://github.com/juanrocha/panarchy.代码本和数据库可以在公共在线存储库中找到<一个href="https://doi.org/10.6084/m9.figshare.13490919" target="_blank" rel="noopener">https://doi.org/10.6084/m9.figshare.13490919.
文献引用
艾莉森,h。E。和r。霍布斯,2004年。弹性,适应能力,以及”锁定陷阱”西澳大利亚农业区。生态与社会9(1):3。<一个href="https://doi.org/10.5751/ES-00641-090103" target="_blank" rel="noopener">https://doi.org/10.5751/ES-00641-090103
A. V. Banerjee和E. Duflo, 2012。贫穷经济学:对抗全球贫困方式的彻底反思。公共事务,纽约,纽约,美国。
Banerjee, A., E. Duflo, N. Goldberg, D. Karlan, R. Osei, W. Parienté, J. Shapiro, B. Thuysbaert和C. Udry. 2015。来自六个国家的证据表明,一个多层面的项目为非常贫穷的人带来了持久的进步。科学348(6236):1260799 - 1260799。<一个href="https://doi.org/10.1126/science.1260799" target="_blank" rel="noopener">https://doi.org/10.1126/science.1260799
2012年。概率主题模型。计算机协会通讯55(4):77-84。<一个href="https://doi.org/10.1145/2107736.2107741" target="_blank" rel="noopener">https://doi.org/10.1145/2107736.2107741
布莱,博士,吴a.y., m.i.乔丹。2003。潜在狄利克雷分配。机器学习研究杂志:993-1022。
Bowles, S., S. N. Durlauf和K. Hoff, 2006。贫困陷阱。普林斯顿大学出版社,美国新泽西州普林斯顿。<一个href="https://doi.org/10.1515/9781400841295" target="_blank" rel="noopener">https://doi.org/10.1515/9781400841295
Bryman, a . 2008。社会研究方法。第三版。牛津大学出版社,英国牛津。
S. Carpenter, B. Walker, J. M. Anderies和N. Abel, 2001。从隐喻到测量:什么对什么的弹性?生态系统4:765 - 781。<一个href="https://doi.org/10.1007/s10021-001-0045-9" target="_blank" rel="noopener">https://doi.org/10.1007/s10021-001-0045-9
卡斯特尔,W. Z.和H.施伦克,2020年。计算自适应周期。10:18175科学报告。<一个href="https://doi.org/10.1038/s41598-020-74888-y" target="_blank" rel="noopener">https://doi.org/10.1038/s41598-020-74888-y
克拉克,W. C.和A. G.哈利,2020年。可持续发展科学:走向综合。环境与资源年度审查45(1):331-386。<一个href="https://doi.org/10.1146/annurev-environ-012420-043621" target="_blank" rel="noopener">https://doi.org/10.1146/annurev-environ-012420-043621
迪林,j.a. 2008。景观变化与恢复力:云南的古环境评价全新世18(1):117 - 127。<一个href="https://doi.org/10.1177/0959683607085601" target="_blank" rel="noopener">https://doi.org/10.1177/0959683607085601
Feinerer, I.和K. Hornik, 2020。tm:文本挖掘包,R包版本0.7-8。<一个href="http://tm.r-forge.r-project.org" target="_blank" rel="noopener">http://tm.r-forge.r-project.org
Feinerer, I., K. Hornik和D. Meyer, 2008。基于文本挖掘的数据挖掘方法研究。统计软件学报25(5):1-54。<一个href="https://doi.org/10.18637/jss.v025.i05" target="_blank" rel="noopener">https://doi.org/10.18637/jss.v025.i05
Folke, c . 2016。弹性(转载)。生态与社会21(4):44。<一个href="https://doi.org/10.5751/ES-09088-210444" target="_blank" rel="noopener">https://doi.org/10.5751/ES-09088-210444
福克斯,j.w. 2013年。应该放弃中间扰动假说。生态学报28(2):86-92。<一个href="https://doi.org/10.1016/j.tree.2012.08.014" target="_blank" rel="noopener">https://doi.org/10.1016/j.tree.2012.08.014
González, J. A., C. Montes, J. Rodrı́guez,和W. Tapia. 2008。重新思考作为一个复杂的社会-生态系统的加拉帕戈斯群岛:对保护和管理的影响。生态与社会13(2):13。<一个href="https://doi.org/10.5751/ES-02557-130213" target="_blank" rel="noopener">https://doi.org/10.5751/ES-02557-130213
格里菲斯,T. L.和M.斯蒂弗斯,2004。找到科学的主题。美国国家科学院学报101:5228-5235。<一个href="https://doi.org/10.1073/pnas.0307752101" target="_blank" rel="noopener">https://doi.org/10.1073/pnas.0307752101
Grün, B.和K. Hornik. 2011。topicmodels:一个适合主题模型的R包。统计软件学报40(13):1-30。<一个href="https://doi.org/10.18637/jss.v040.i13" target="_blank" rel="noopener">https://doi.org/10.18637/jss.v040.i13
Grün, B.和K. Hornik, 2021年。Topicmodels:主题模型,R Package Version 0.2-12。<一个href="https://cran.r-project.org/web/packages/topicmodels/index.html" target="_blank" rel="noopener">https://cran.r-project.org/web/packages/topicmodels/index.html
甘德森、l.h.、c.r. Allen和A. Garmestani, 2022年。应用全方位:跨学科的应用和扩散。岛出版社。
甘德森,L. H.和C. S.霍林,2002。Panarchy。一个小岛,华盛顿特区,美国。
汉森,s.o. 2017。科学和伪科学。E. Zalta,编辑。斯坦福哲学百科全书。美国加州斯坦福大学形而上学研究实验室。<一个href="https://plato.stanford.edu/archives/sum2017/entries/pseudo-science/" target="_blank" rel="noopener">https://plato.stanford.edu/archives/sum2017/entries/pseudo-science/
C. S. Holling 1986。陆地生态系统的恢复力:局部意外和全球变化。编辑W. C.克拉克和R. E.穆恩的292-317页。生物圈的可持续发展。剑桥大学出版社,英国剑桥。
霍林,c.s. 2001年。理解经济、生态和社会系统的复杂性。生态系统4:390 - 405。<一个href="https://doi.org/10.1007/s10021-001-0101-5" target="_blank" rel="noopener">https://doi.org/10.1007/s10021-001-0101-5
Holling, c.s., l.h. Gunderson和G. Peterson, 2002。可持续性和panarchies。63-102页,L. H.甘德森和C. S.霍林编辑。Panarchy:理解人类和自然系统的转变。一个小岛,华盛顿特区,美国。
C. S. Holling和G. K. Meffe, 1996。指挥与控制与自然资源管理的病理。保护生物学10(2):328 - 337。<一个href="https://doi.org/10.1046/j.1523-1739.1996.10020328.x" target="_blank" rel="noopener">https://doi.org/10.1046/j.1523-1739.1996.10020328.x
Hornik, k . 2020。自然语言处理基础设施,R Package Version 0.2-1。<一个href="https://cran.r-project.org/web/packages/NLP/index.html" target="_blank" rel="noopener">https://cran.r-project.org/web/packages/NLP/index.html
马丁,R.和P.桑利,2011。概念化集群演化:超越生命周期模型?区域研究45(10):1299 - 1318。<一个href="https://doi.org/10.1080/00343404.2011.622263" target="_blank" rel="noopener">https://doi.org/10.1080/00343404.2011.622263
Maru, Y. T., C. S. Fletcher, V. Chewings, 2012。综合现有的陷阱方法是有用的,但需要重新考虑土著劣势和贫困研究。生态与社会17(2):7。<一个href="https://doi.org/10.5751/ES-04793-170207" target="_blank" rel="noopener">https://doi.org/10.5751/ES-04793-170207
Moen, J.和E. C. H. Keskitalo, 2010。瑞典多用途北方森林中的环环相扣的大草原。生态与社会15(3):17。<一个href="https://doi.org/10.5751/ES-03444-150317" target="_blank" rel="noopener">https://doi.org/10.5751/ES-03444-150317
帕克,J. N.和E. J.哈克特,2012。科学合作和社会运动中的热点和热点时刻。美国社会学评论77(1):21-44。<一个href="https://doi.org/10.1177/0003122411433763" target="_blank" rel="noopener">https://doi.org/10.1177/0003122411433763
雷德曼,c.l.和a.p. Kinzig, 2003。过去景观的恢复力:恢复力理论,社会和舌头duree.保护生态7(1):14。<一个href="https://doi.org/10.5751/ES-00510-070114" target="_blank" rel="noopener">https://doi.org/10.5751/ES-00510-070114
Robinson, D.和J. Silge, 2021年。tidytext:文本挖掘使用dplyr, ggplot2和其他整洁工具,R包版本0.3.3。<一个href="https://github.com/juliasilge/tidytext" target="_blank" rel="noopener">https://github.com/juliasilge/tidytext
Rocha, j.c.和R. Wikström。2015.探测与生态制度变化有关的生态系统服务的潜在影响-只是一个措辞问题。《J. C. Rocha,人类世的政权变迁》94-113页。博士论文,斯德哥尔摩大学斯德哥尔摩弹性中心,瑞典斯德哥尔摩。
Simmie, J.和R. Martin, 2010。区域的经济弹性:走向进化的方法。《经济与社会学报》3(1):27-43。<一个href="https://doi.org/10.1093/cjres/rsp029" target="_blank" rel="noopener">https://doi.org/10.1093/cjres/rsp029
斯特林格,L. C., A. J. Dougill, E. Fraser, K. Hubacek, C. Prell, M. S. Reed。拆包”参与”社会生态系统的适应性管理:一个批判性的评论。生态与社会11(2):39。<一个href="https://doi.org/10.5751/ES-01896-110239" target="_blank" rel="noopener">https://doi.org/10.5751/ES-01896-110239
曾国刚,高杰,L. Shekhtman,郭胜,吕文武,吴杰,刘洪,O. Levy,李丹,高震,等。2020。城市交通中的多重亚稳态网络状态。美国国家科学院学报117(30):17528-17534。<一个href="https://doi.org/10.1073/pnas.1907493117" target="_blank" rel="noopener">https://doi.org/10.1073/pnas.1907493117
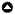
图1

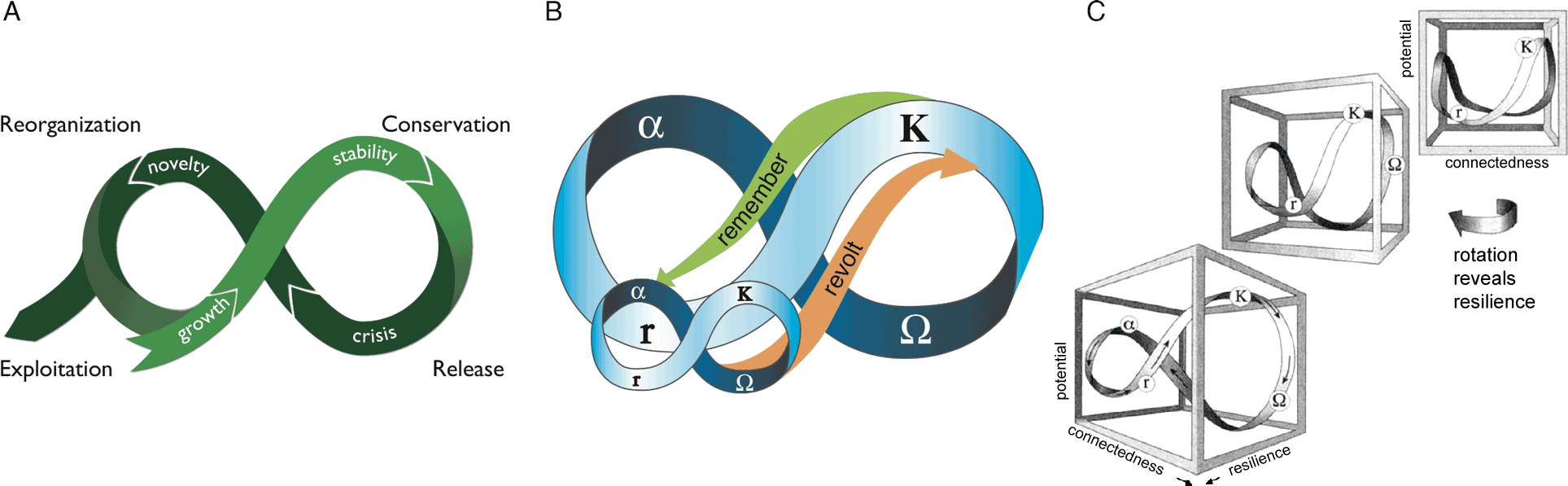
图1.Panarchy是一种启发式的嵌套自适应循环,服务于表示各种系统和环境问题。不同层级(A)的适应性循环(B)可以通过记忆和反抗跨尺度互动联系起来。(C)将适应周期与潜能、连通性和恢复力轴联系起来Panarchy由Lance Gunderson和C.S. Holling编辑,©2002岛屿出版社。转载经美国华盛顿特区岛屿出版社许可。<一个href="https://islandpress.org/books/panarchy" target="_blank">https://islandpress.org/books/panarchy
图2
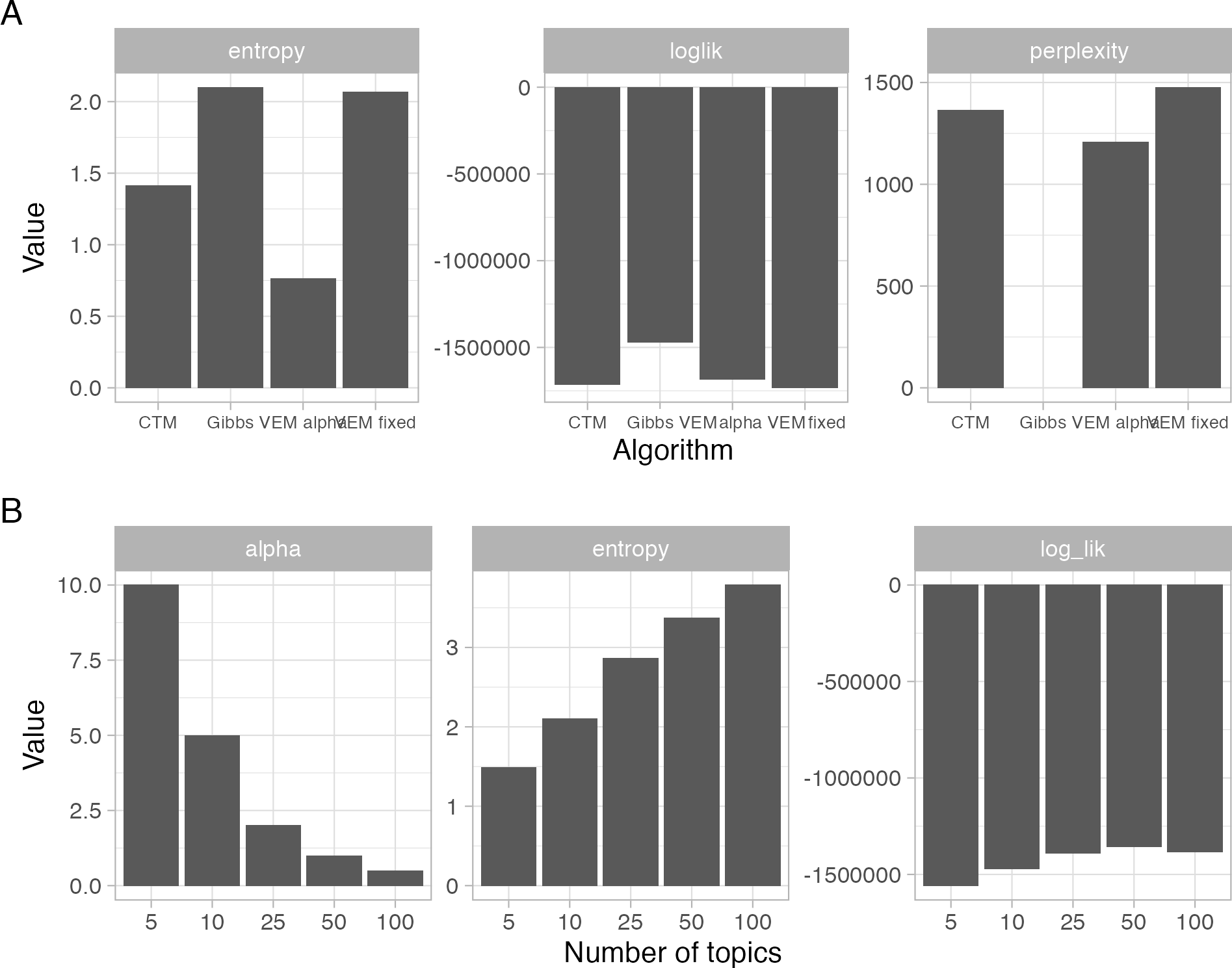
图2.Gibbs抽样最大化了熵和对数似然估计,使其成为适合我们数据的算法(a)。增加主题数量(从5-100)表明α降低,表明尽管主题数量更大,少数主题足以描述大多数论文(B)。对数似然在50个主题中最大化,紧随其后的是25和100。虽然50个主题略好一些,但我们选择了25个,因为α参数表明更喜欢较低的数字,或更精简的解决方案,以避免过拟合。需要注意的是,Gibbs sampling的perplexity是无法计算的,因此A的缺失值和B的缺失值。
图3
图3.随时间推移的Panarchy话题。每年论文数(A), 2019年最多324篇。每年的论文比例(B)和每年的主题内容相对比例(C)对于大多数论文的时间窗口(A中的灰色区域)并没有表现出很强的趋势。(B)中,一条参考横线虚线表示所有主题均占主导地位的水平。根据我们的模型拟合的后验概率,每个主题由最能描述它们的10个单词总结在(D)中。图4展开了(B),展示了每个主题的时间序列。所有时间序列都将2021年排除在外,以解释时间序列末尾人为导致的论文数量下降,如A所示。
图4
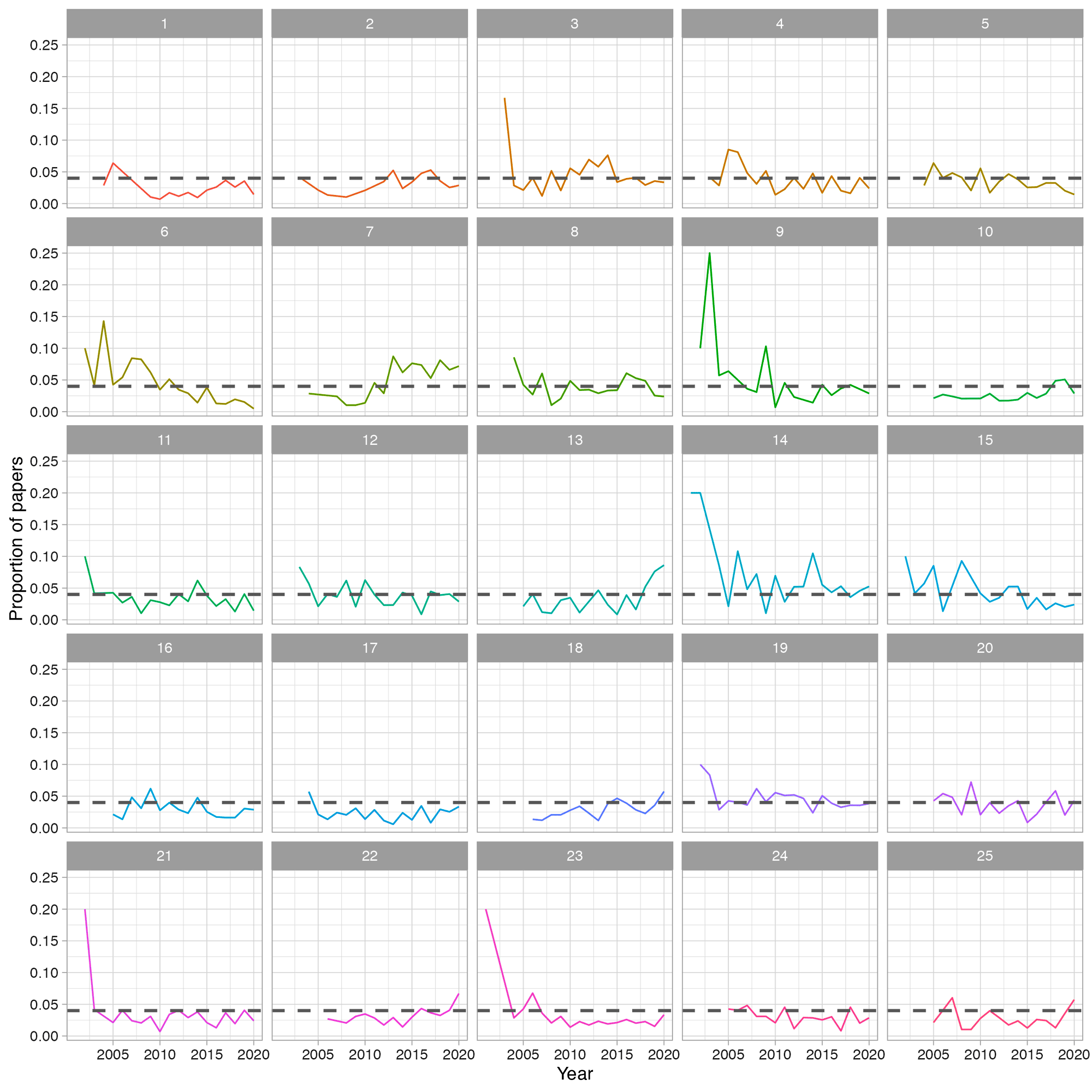
图4.每年每个主题的论文比例。每一行表示某一特定年份的内容占同年发表的所有论文的平均比例。图A1补充了我们样本中每篇论文的主题比例。
图5
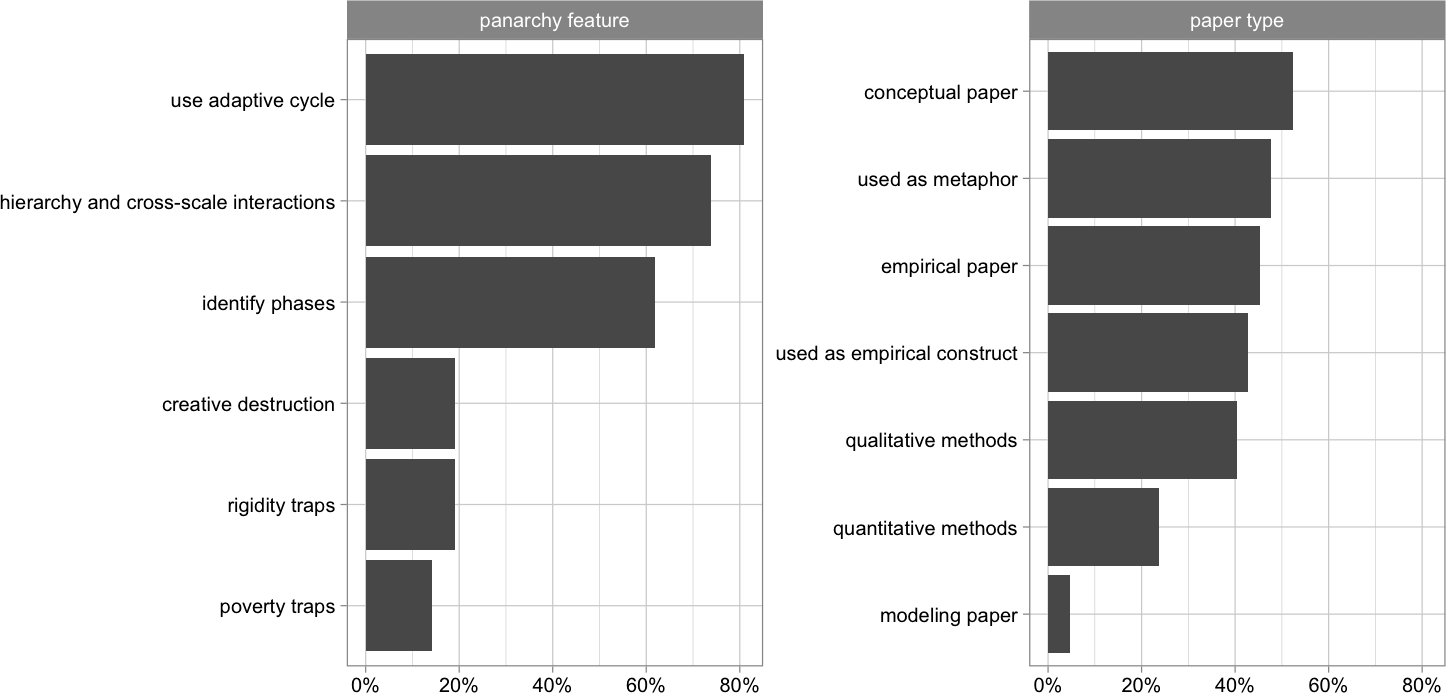
图5.定性的结果。文献分析被用来解开不同的泛结构特征的子样本的论文(N = 42)。超过一半的论文是概念性的工作,大多数实证论文属于定性方法。