去pdf本文的版本
苏安安、梁锦明、欧里森。2021。夏威夷小渔船渔业调查的自动内容分析揭示了微妙的、不断演变的冲突。生态与社会26(4): 9。
https://doi.org/10.5751/ES-12708-260409
夏威夷小渔船渔业调查的自动内容分析揭示了微妙的、不断演变的冲突
摘要
人工内容分析提供了一种系统可靠的方法来分析叙事文本中的模式,但对于较大的数据集,人工编码是不可用的,自动化内容分析方法提供了自动分类文本模式的诱人且省时的解决方案。然而,需要大量的数据集和分析这些大型数据集的复杂性阻碍了它们在渔业科学中的应用。渔业科学家通常处理中等规模的数据集,这些数据集不够大,不足以保证复杂的自动化技术的复杂性,但也不够小,无法进行成本有效的手工分析。对于这些情况,基于字典的自动化内容分析技术可以潜在地简化自动化过程,而不会失去上下文敏感性。在这里,我们构建并测试了一个特定于渔业的数据字典,以在夏威夷小渔船渔业调查中对开放式回答进行自动内容分析,以检查渔业冲突的性质。在本文中,我们描述了该方法的总体性能,创建和应用渔业数据字典,以及该方法的优点和局限性。结果表明,字典方法能够快速准确地将非结构化渔业数据分类为结构化数据,并且在揭示渔业管理中经常含糊不清和被忽视的根深蒂固的冲突方面非常有用。除了为该方法提供概念证明之外,字典还可以在后续的调查浪潮中重用,以继续监测这些冲突的演变。此外,这种方法可以更广泛地应用于渔业和自然资源保护科学领域,为方法学工具箱提供有价值的补充。介绍
与许多自然资源问题一样,管理渔业资源意味着管理人类与鱼类的互动,因此社会背景与生物和生态因素同样重要(Fulton et al. 2010)。为了更好地了解社会问题,渔业管理采用了许多定性信息来源。内容分析是一种常用的分析定性数据并进行有效推断的研究方法。这种分析在历史上一直是手工完成的,研究人员阅读和解释文本数据,并分配主题代码。虽然定性数据分析软件如MAXQDA、NVivo或Atlas。Ti通常用于协助这一过程,对于数据组织,初始编码过程仍然使用软件界面手工进行。我们当前的数字时代给内容分析带来了巨大的变化,也为理解大量文本数据带来了新的可能性。在“大数据”时代,自动化内容分析方法已经出现,可以补充人工方法,尽管它们还没有经常应用于渔业或其他自然资源保护环境。每种方法都有不同的优点和缺点,其中选择哪种方法最适合研究问题,在某种程度上取决于数据集的大小。自动化方法非常适合大数据,因为大数据的规模超过了传统手工方法的能力,并且数据集足够大,可以进行可靠的机器学习。 However, evaluating whether a dataset is “big” can vary by subject domain, variable type, and research questions (Connolly-Ahern et al. 2009, Luke et al. 2011). For example, 1000 tweets could include a lot less information than 10 one-hour interviews. In a fishery context, the size of the dataset is often in a middle ground that cannot be considered “big” enough for reliable use of automated content analysis alone, but it isn’t “small” enough for traditional manual content analysis to be cost-effective. This article provides guidance for a modified automated approach that can be applied to moderately sized datasets such as those typical in the field of fishery science and other conservation issues.
研究渔业科学中的社会问题通常依赖于人工内容分析(MCA)来系统地组织从叙述文本中出现的模式(Kamhawi和Weaver 2003)。MCA允许研究人员通过手动编码文本单元来分析数据并解释其含义,然后从编码单元的出现中构建概念。作为一种研究方法,MCA代表了一种描述和量化显著概念的系统方法(Elo和Kyngäs 2008)。通过将长文本提炼成更少的与概念相关的类别,研究人员可以检验理论并增强对当前主题的理解。范畴作为一个概念系统,揭示内容的潜在含义,并从文本中得出有效的推论。然而,该方法有局限性,即对于较大的数据集,它是昂贵的和时间密集的。手工内容分析的成本大致与所分析的数据量成正比。
自动内容分析(ACA)可以通过使用机器学习的力量来分析文本来提高效率。ACA的初始成本很高,但一旦建立,增加数据量几乎不需要额外的分析工作(Trilling和Jonkman 2018)。用于处理不断增长的数据集的数字文本分析自动化工具已经取得了令人印象深刻的进展。一些流行的ACA方法是有监督和无监督机器学习算法,它们在处理大型文本数据时扩展了人工分类的能力(Maier等人,2018年)。尽管有监督和无监督机器学习技术能够以一致和可扩展的方式对文本内容进行分类,但两者都需要足够大的数据集来构建准确可靠的编码方案。在渔业科学等领域,数据集通常处理中等规模的数据集,这些数据集不够大,不足以保证开发复杂的机器学习算法。
字典方法是一种更简单和直接的ACA方法,可用于分析中等大小的数据集。它机械化了一个自定义类词词典,其中包含代表类别或主题结构的关键字和短语。然后软件读取语料库;每当字典遇到一个特定的单词,它就会被统计并归类到那个结构中(Deng et al. 2017)。因此,在对中等大小的数据使用字典方法时,成功将依赖于数据集中使用的一致的技术术语。词典技术一直是社会科学家在一些领域的有用工具,如旅游研究分析开放式回答(Stepchenkova et al. 2009),农业分析政策法规(Robson and Davis 2014),政治学分析发言(Grimmer and Stewart 2013),医学分析论坛上的药物评论(Asghar et al. 2013)。然而,这种技术有一些局限性。字典仍然需要几个主观步骤来开发字典和相关的类别。此外,单词在不同的上下文中有不同的含义,确定一个单词有多少种不同的分类方式可能具有挑战性。尽管有这些限制,字典ACA方法可能非常适合于我们通常在渔业环境中看到的定性数据类型,原因有两个。 First, social issues within a fishery are relatively predictable and limited in scope. The limited breadth of conflict topics that typically arise from fishery datasets consistently use key terms throughout the narrative text to denote that specific topic. A fishery-specific dictionary could include the industry-specific terms while being sensitive to the semantics that may vary from common usage in the English language. Second, the moderate dataset size lends itself to a dictionary approach. To manually create the dictionary, researchers only need to read a subset of text and discover the most covered topics for analysis.
为了在渔业环境中扩展ACA应用程序,我们构建并测试了一个特定于渔业的词典,以对夏威夷小渔船渔业调查中开放式回答中确定的冲突进行自动内容分析。具体来说,我们的数据集包括2007年和2014年由美国国家海洋和大气管理局(NOAA)下属的太平洋岛屿渔业科学中心(PIFSC)进行的两项社会经济调查。调查的主要目的是评估渔业的经济、社会和文化特征。调查的受访者是持有夏威夷州商业海洋执照的渔民,他们使用小船(通常在40英尺以下)捕鱼,并在调查的相应年份出售了至少一条鱼(Hospital等人,2011年,Chan和Pan 2017年)。来自夏威夷所有岛屿的渔民的反馈被记录下来,包括人口统计信息、船只特征、捕鱼活动、捕鱼动机等。像许多渔场一样,夏威夷人的小船渔场也经历了管理选择上的冲突。一个开放式的调查问题是,“你对夏威夷人的渔业应该如何管理或你觉得需要进一步研究的主题有什么建议吗?”以前对广泛的资源主题进行了调查,但商业渔民、非商业渔民和管理人员之间的冲突迹象表明,对反应进行更有力的分析可以增进对冲突驱动因素的理解。这个数据集非常适合评估基于字典的ACA方法作为分析中等规模数据集的有效方法的效用,因为它既足够大,可以包含一系列主题和主题,又足够小,可以有效地将结果与手动编码进行比较。
方法
为了协助MCA和ACA研究过程,我们使用了Provalis研究作为我们的数据分析平台。Provalis Research是为数不多的定性数据分析平台之一,它包括创建自定义数据字典的能力,可以与手动内容分析交互。我们使用了来自Provalis Research的两种不同类型的软件来协助编码、注释和字典构建。QDA挖掘器5.0.23允许我们进行MCA,而WordStat 8.0.16用于为ACA创建自定义渔业冲突字典。由于这两种不同类型的软件来自同一家公司,因此它们可以无缝地相互通信,以方便分析。该项目的元数据可通过NOAA的InPort企业管理系统(PIFSC 2021)获得。
渔业冲突概念框架
在分析任何文本语料库时,强大的概念框架有助于内容分析过程,为研究问题和分析提供理论基础,并可能具有深刻见解的数据分类、主题和代码(Green 2014)。我们使用了Madden和McQuinn的冲突模型,该模型将冲突分为三个层次,将驱动因素分为三个维度。图1展示了Madden和McQuinn(2014)模型的修改版本,该模型将冲突分为三个层次:争议、潜在冲突和基于身份的冲突。争议级别是直接的,代表有形的问题或分歧。潜在的冲突增加了另一层复杂性,其中冲突继承了以前未解决的争端的意义,从而增加了当前局势的重要性。基于身份的冲突包括定义个人身份的价值观、信念和目标。在资源冲突中,资源的使用与身份深深交织在一起,如果人们感到自己的社会身份或对资源的获取受到威胁,他们就会强烈抵制。如果这些潜在的和基于身份的冲突没有得到解决,冲突可能会持续存在,甚至恶化(Madden和McQuinn 2014)。然而,潜在的和基于身份的冲突不容易明确表达,也不容易准确识别。人们主要表达的是有形的争议程度。 This often leads to conflict resolution approaches designed to focus on substantive disputes, which can perversely increase social tension among stakeholder groups, erode trust and common understanding, and ultimately contribute to a decline in fish stocks (Pomeroy et al. 2007, Murshed-e-Jahan et al. 2014, Spijkers et al. 2018). Madden and McQuinn complement their levels with three dimensions of conflict that may be driving environmental conflicts to deeper and often invisible levels and thus must be addressed by management (Madden and McQuinn 2014; Fig. 1): “substance,” directly addressing the dispute level, “relationships,” the personal conflicts and the quality of the relationships (trust or level of respect) between stakeholders, and “process” used to enhance decision-making design, equity, and implementation. We overlaid the dimensions of conflict on the levels of conflict to illustrate that successful management responses need to address substance, relationships, and process dimensions together at each of the dispute, underlying, and identity-based conflict levels. Although it is difficult to accurately decipher the deeper levels of conflict through fishers’ responses, dimensions can be easier to interpret. Therefore, the following methods use the substance, relationships, and process dimensions to guide the manual content analysis processes and indirectly tackle deeper levels of conflict.
手工内容分析
我们首先将人工内容分析应用于单个数据集,即PIFSC 2014年的小船渔业调查(373份回复),通过开放编码的抽象过程和创建更高阶的主题。我们使用扎根理论(Charmaz 2006, Glaser和Strauss 1967)对开放式评论进行编码,扎根理论从观察中发展理论。继Erlingsson和Brysiewicz(2017)之后,我们手动将注释、标题和描述性标签附加到与冲突框架相关的内容上,因为它们是从数据中出现的。当我们开始看到类似的想法被重复时,我们将标签细化为一致的代码,重新访问数据以确保标签的应用一致。最终的代码表示通过管理建议描述冲突的具体概念,并帮助组织内容的基本含义。
下一步是通过将与上面讨论的冲突框架相关的代码分组,将代码组织成更高阶的主题。与渔业内部直接争端或冲突有关的主题被归入实质性维度。关系维度下的主题涉及渔业内不同行动者的互动,以及与决策设计相关的过程主题,以及公平感知。从代码到主题,再到总体框架的维度,每一个不断增加的抽象级别都阐明了文本中的不同概念,并从数据集中生成广泛或特定的知识(Bengtsson 2016, Cavanagh 1997)。最终的编码方案包含冲突框架维度相关的20个编码和7个主题(表1)。
一个受访者的评论可能包含多个代码。例如,以下评论将被编码为准入问题、过度捕捞和指责网渔者,它们属于冲突框架中的实质和关系维度:
如果我们有配额,为什么还要有这么深的禁区。就我个人而言,我认为不应该有限制区域,而应该有一个配额。我认为Opelu和Akule网应该被禁止。多年来,我们在夜间捕捞这两种鱼类时看到的鱼数量严重下降。我曾见过网子把整群的鱼捞上来。是的,如果你禁止这些渔网,大约会有10人失业,但总的来说,未来会有成千上万的人享受捕捞和食用这些鱼。这是关于维持和渔网正在消耗物种。
附加到同一注释的多个代码称为共现。检查编码共现可以表明文本中可能存在隐含的沟通模式(Armborst 2017),并可以洞察代码、主题和更广泛维度之间的关系。
在整个编码过程中,我们与研究团队讨论了代码的开发以及它们之间的关系。所有编码和分析均由第一作者进行,以保持内部一致性。
构建和测试自动化内容分析
为了构建自定义词典,研究人员需要在感兴趣的文本中识别正确的单词和短语,并将它们分配到各自的代码中。我们已经从叙述文本中识别出了代码;在这里,我们从手工编码开发了一个自定义字典,将字典应用于未分类的2007数据集,以自动编码分类,并评估MCA和字典辅助ACA的表现。
词典建设
构建字典的第一步是对数据集进行预处理,为进一步分析准备语料库。我们采用了两种预处理技术:拼写检查和停止词删除。首先,简单地纠正了整个数据集的拼写错误。语义意义不大的停止词(“a”、“the”、“and”等)被放入排除列表,指示计算机忽略这些单词(Deng et al. 2017)。经过处理的数据集允许研究人员检查最常见的关键字,并根据相关含义将它们分配给特定的代码。
数据字典由三个主要元素组成:“条目(单词和短语)、类别以及条目和类别之间的关联”(Deng et al. 2017:952)。前一节中的手动编码产生了在冲突概念框架维度指导下的特定代码。在这一步中,我们识别出与这些代码相关的核心单词和短语,并将它们放入相应的字典代码中。字典中的每个条目都充当代码类别的指示符。一个字典条目在Provalis Research中被称为“关键字”,可以由单词或短语组成。字典假设特定文本单元的意义仅依赖于该特定关键字的出现。例如,如果渔业调查显示了一个“经济”类别,那么经济类别的关键字条目列表可能包括:“成本”、“昂贵”、“价格”、“谋生”等。
尽管我们发现关键字和短语通常可以封装类别的正确含义,但使用字典的自动分类可能会触发类型I错误(假阳性)。自定义接近规则可以通过提高概念的整体精度来帮助调节第一类错误的数量。我们数据集中的一个代码“overfish”在用于否定时很可能会引发假阳性。如果渔民的直接回答是:“鱼被过度捕捞了”,软件就会检测到“过度捕捞”这个词,并正确地将其归入预定的“过度捕捞”类别。但是,如果回答是“鱼没有被过度捕捞”,软件就会错误地将回答归入过度捕捞类别。为了解释这种影响,我们创建了一个规则,其中“过度捕捞”代码下的关键字只有在同一句话的五个单词内没有前面有否定(no, not, never等)时才为真。
最后,为了扩展数据字典的功能,我们对其进行了同义词和反义词扩展。同义词和反义词引申相对简单;WordStat 8.0.16中的一个特性可以将特定单词的同义词和反义词添加到数据字典中。然后,我们评估每个建议,以决定是否应该将条目添加到最终的字典中,最终增加对其他未分类数据集的适用性。
验证和准确性评估
在将字典直接应用于未分类的数据集之前,应该对其进行验证。在第一轮验证中,我们使用关键字上下文工具(KWIC)来评估字典在2014年数据集上的性能。KWIC工具在其原始上下文中显示每个自动分类的关键字。然后,研究人员可以评估每个特定的单词是否被准确地归类到适当的代码中。自动编码和人工编码结果之间的相似性是字典有效性的主要指标(Deng et al. 2019)。对于每个自动分类,我们将自动应用的代码与手动代码进行比较。然后我们计算每个代码的正确分类的百分比。不出所料,与手动编码相比,自动编码是准确的,因为数据字典是根据2014年数据集中出现的手动代码构建的。但是,这是确保字典不会触发误报的必要步骤,因为关键字在不同的上下文中可能有不同的含义。
我们词典的最终目的是为了便于以后的分析。一旦我们确认字典在其衍生数据集上表现良好,我们就将其应用于2007年NOAA的一项类似的小型渔船渔业调查,以评估它在单独数据集上的准确性。因为我们没有对2007数据集进行MCA,所以我们依赖于KWIC工具来显示与整个响应相关的每个自动化代码。我们没有比较手动编码来确定准确性,而是确定每个自动化分类是否符合表1中编码本的定义。我们通过计算每个代码被正确分类的次数与它在数据集中被检测到的总次数的比例来确定每个代码的准确性。为了自信地将数据字典应用于不同的未分类文本,自动编码需要在至少80%的时间内成功地将条目归类到正确的类别(Bengston和Xu 1995, Young和Soroka 2012, Deng et al. 2017)。
冲突分析
一旦这两个数据集被分类,我们项目的最后一步是使用我们的分析结果来检查一些渔业管理相关的问题。我们首先调查了代码的比例是否随着时间的推移而变化,以及/或在同一年内代码是否因动机而不同。每个调查答复都被分配了一个唯一的标识号,并根据动机分为商业渔民和非商业渔民。尽管所有受访者都持有夏威夷州商业海事执照,但以往的研究表明,这并不一定意味着他们被认定为商业渔民(Leong et al. 2020)。由于身份是冲突的更深层次之一,我们根据对渔民如何定义自己为渔民这个问题的回答对他们进行了分类。回答全职商业或兼职商业的人被归类为商业渔民。那些回答娱乐费用、纯粹娱乐、生存或文化的人被归类为非商业渔民。我们将娱乐消费的渔民归为非商业类别,因为即使他们卖鱼来抵消汽油、冰和诱饵等费用,他们的主要动机是娱乐,而不是盈利。有三位受访者没有回答这个调查问题,因此没有被包括在本次分析中。由于两个数据集之间的渔民动机的样本量,我们使用多项logit模型来解释嵌套数据的变化。
第二个问题来自冲突框架理论,该理论认为更深层次的冲突往往隐藏在更容易表达的表面争端中。理解冲突的各个维度是如何相互关联的,可以帮助我们从有形的实体维度准确地解读冲突的无形驱动因素。为了检查每个维度之间的关系,我们测量了代码之间共同出现的实例。我们使用内置的代码共现工具来检查调查响应中代码的接近性,与实质、关系和过程维度相关。我们使用了Sorensen系数相似指数,这是一个统计数据,使用以下公式比较不同样本之间的相似性:
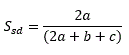 |
(1) |
其中a表示两项都出现的情况,b和c表示一项出现而另一项不存在的情况,以确定两个代码在整个文本样本中同时出现或重叠的频率和一致性。系数可以取0(表示没有编码重叠)和1(表示完全重叠)之间的值。
结果
结果证明了词典在渔业科学领域的“概念证明”,结构如下:(1)我们展示了完全开发的夏威夷小船渔业词典,并评估了应用词典对非分类调查的准确性,(2)我们说明了两个数据集的具体内容分析结果,(3)我们回答了渔业管理相关问题。
数据字典
我们在完全开发的数据字典中确定了274个关键字(表2),146个关键字属于物质类别,73个关键字属于关系,55个关键字属于过程。表2显示了对每个预先指定的编码类别的关键字分配。包含*符号的单词包括该词根后面的所有字母。例如,“enforc*”将匹配单词“强制”、“强制”、“强制”和“强制”。#符号代表单个数字,其中两个##符号代表这两个数字的任何组合。例如,“under ##”包含“under 10”[磅]、“under 15”[磅]、“under 20”[磅]等短语。词典中唯一嵌入的规则是用来解释调查回答中对“过度捕捞”代码下的单词的否定。该规则将2007年数据集的可靠性从没有该规则的79%提高到96%,将2014年数据集的可靠性从84%提高到92%。
评估ACA的准确性
表3按每个抽象级别显示了自动化技术的准确性。2014年数据集的总平均准确度为92%,2007年数据集的总平均准确度为89%。分解后,物质、关系和过程维度的准确性在2014年分别为92%、93%和88%,在2007年分别为92%、88%和83%。2014年更高的性能可以解释为字典是基于该数据集开发的。缩小抽象级别,我们发现某些类别比其他类别更准确。“缺乏传统知识”、“不信任”和“夏威夷小渔船渔业不是问题”这三个类别的准确率分别只有76%、78%和79%,低于我们的有效性标准。2007年和2014年数据集中的所有其他类别都符合成功验证的标准。
专题分析
对2014年调查的所有373份回复都被手动编码为物质、关系和过程维度下的七个突出主题。在实质方面,我们有政策和监管问题,财政困难,资源可持续性。人际关系会产生外部冲突和内部冲突。过程涉及无效的决策设计,以及当地人感觉被边缘化(表3)。这些主题也为2007年调查中281份回复的自动内容分析奠定了基础。从自动分析中得出的主题在不同年份之间保持不变,但在不同的调查年份中,被引用的主题的频率有所不同。
物质:
实质层面包括三个主题:政策和监管问题、财政困难和资源可持续性。2014年,在政策和监管问题的主题下,最常见的代码是缺乏对基础设施的维护(n = 95;占总报表的25%;表4):
拖车划船的基础设施最少。其他州的划船设施比我们这个岛国要好。鱼类聚合装置(FADs)的使用对于为渔民提供目的地至关重要。突然之间,许多这样的设备都没有被重新部署。这迫使渔民走得更远,燃烧更多的燃料来捕鱼,从而导致经济困难。
然而,在2007年,最常见的陈述是关于封闭渔区的准入问题(n = 72;26%),例如,“Bottom Fish闭包是个坏主意,真的不公平,这就是(我们的)生活方式。”
在2014年的物质类别中,第二个最常见的主题是提高各种鱼类的大小和重量限制(n = 73;20%)。在这一主题下的发言对捕捞小鱼表示关切。许多人认为这在环境上是不可持续的,并助长了过度捕捞,例如,“夏威夷人需要限制所有出售的ahi鱼的大小。不小于繁殖体大小。有太多的幼鱼被捕杀以获取利润。明天呢?”然而,在2007年的数据集中,增加特定鱼类的大小和重量限制的政策建议大幅减少,n = 20只占总响应的7%。
经济困难已成为渔民关心生计的经济实质问题(2014年:n = 64,17%;2007: n = 44, 16%):
渔网可以消灭整个鱼群,什么也不留下。人们说我们将无法满足对鱼的需求,这将推高价格。据我所知,我们的价格仍然和80年代一样,而费用却上涨了400%。
渔民普遍表达了过度捕捞的严重性以及为未来保护海洋资源的必要性,这导致了资源可持续性的主题(2014:n = 61;16% 2007: n = 37;13%),例如,“如果我们想为后代捕鱼,那么也许应该对延绳钓有更多的限制。”
关系:
关系维度分为外部冲突和内部冲突两个主题。外部冲突被定义为渔民与管理层之间的纠纷,渔民对管理层表示不信任。内部冲突被定义为渔民之间基于渔具类型的纠纷。不信任代码是外部冲突中最突出的代码,在渔民和管理人员之间产生社会紧张关系(2014:n = 34,9%;2007: n = 51, 18%),例如,“科学家真可耻,他们应该为故意歪曲数据和让政府为从来不需要任何研究买单而负责,”以及,
联邦法规应该更新。别再愚弄公众了,拿出正确的数字。如果他们继续这样做,谁知道他们还会保护什么,并开始禁止其他物种。这就是问题所在,当政府不进入海洋并制定所有规则时。
在内部冲突主题下,最突出的陈述是渔民指责延绳钓船(2014:n = 37,10%;2007年:n = 64,23%)和渔民指责网捕者(2014年:n = 39,10%;2007: n = 37, 13%)。这些守则下的声明指责延绳渔船和渔网渔船过度捕捞、监管行动增加以及对其生计的后续影响:
延绳船限制了进入这些岛屿的鱼类数量。也许延绳钓鱼可以限制每天捕捞的磅数。当我拨打自动鱼类拍卖录音,听到一艘船将38,000磅鱼拖到拍卖现场这样的数字时,我不得不相信这一定会对到达岛上的鱼的数量产生影响。如果不是延绳钓,那么需要实施其他一些法规,以确保休闲渔民有一个更光明的未来。
停止在卡内奥赫湾的网捕鱼!渔人整夜撒网,第二天早上再捞起渔网,耗尽了近海渔业资源。
过程:
过程维度显示了无效决策设计的主题(2014:n = 43,11%;2007年:n = 32,11%),在州和联邦一级都提出了反对意见,理由是公平问题、渔民缺乏发言权以及在实施政策之前需要进行更多研究。过程维度下的另一个主题是当地人感到被边缘化(2014年:n = 27.7%, 2007年:n = 39.14%),因为当地人在捕鱼中流离失所,以及缺乏传统的管理知识,例如,“更多的公共会议和互动,以便渔业部门可以直接从渔民那里获得投入。”
冲突分析
虽然所有受访者都持有夏威夷商业海事执照,但他们从事渔业活动的动机各不相同。2014年,211人(57%)自认为商业渔民,158人(43%)自认为非商业渔民(纯娱乐、娱乐消费、生活和文化)。2007年,118名(42%)渔民被认定为商业渔民,163名(58%)渔民被认定为非商业渔民。考虑到我们的数据集之间的动机差异,以及调查年份的不平衡数据集,我们使用多项logit模型测试了相互作用的显著性。没有发现,我们继续用二项式模型。我们使用二项logit模型来确定27种总分类中是否有任何一种因动机(商业vs.非商业)和年份而不同。在评估的27种分类中(见附录1),2007年只有4种动机在统计上有显著差异,2014年有4种(表4)。在分析2007年与2014年所有利益相关者之间的差异时,有14种代码在所有维度上都具有统计显著性(表4)。
计算编码共现系数,以确定整个文本样本中每个维度与其他维度共现的频率,以探索这些关联从2007年到2014年的变化程度。将所有编码按尺寸进行分组,然后计算尺寸共现率。编码共现系数在2014年低至0.228,在2007年高至0.51(表5)。系数数越高,表明两个维度的重叠程度越高,即在2007年,个体提出物质问题的51%的时候,他们也提出了关系问题。关系-实质系数高于过程系数,但2014年低于2007年。2014年工艺-物质系数和工艺关系系数最低。
讨论
手动文本分析通常用于自然资源环境,耗时长,不适用于较大的数据集。自动化内容分析提供了另一种选择,利用计算能力快速有效地分析大型数据集。不幸的是,来自许多自然资源管理上下文的数据集不够大,无法从大多数ACA技术的效率中受益。在这项研究中,我们展示了字典ACA作为自然资源问题MCA的补充的好处。字典方法旨在丰富(而不是取代)人类编码员的工作,使研究人员能够在保持理论驱动的同时处理更大的数据体。在这里调查的案例中,该方法保留了MCA的优势,同时最大限度地提高了ACA的效率,最终为夏威夷小船渔业冲突的本质提供了有趣的含义。
字典方法在2014年数据集的总平均准确度为92%,在2007年数据集的总平均准确度为89%,这表明该方法可以很好地协助后续的自动化调查。扇区的各个方面都考虑到了字典方法的实用性。首先,渔业环境中的冲突域是可预测的,由重复的关键技术术语组成,主题随着时间的推移保持相对停滞,所有这些都有助于字典方法的有效性。通常,使用单词计数方法,字典中的小条目通常很少有命中,无法产生有意义的结果。然而,相对较少的关键渔业冲突词迅速将字面定义转变为与管理更相关的概念框架。其次,字典的构建方式对于增加字典方法的洞察力很重要(Deng et al. 2019)。在我们的例子中,我们使用了来自MCA初始阶段的主题和代码来为夏威夷小船渔业构建字典。这些主题和代码的灵感来自于一个概念框架。这是典型字典过程的反转,我们认为与其他形式的ACA相比,它提供了更强的演绎能力(Boumans和Trilling 2016)。通常,字典方法首先分析单词的频率,然后根据最流行单词的定义,研究人员为字典中包含的每个关键字确定类别结构(Deng et al. 2017)。 Instead, we first manually classified codes to deductively gain specificity from the context of the text, thereby ensuring that the words chosen in the dictionary-maintained sensitivity to contextual nuance while still preserving the strengths of ACA. This process not only proved validity to automate future Hawaiian small boat surveys but can provide salient insights into the nature of conflict within the fishery.
我们的结果揭示了渔民确定的实质性问题,与有形问题或冲突本身直接相关的陈述,主要与政策和监管纠纷有关。这些结果是意料之中的,因为调查问题的具体目的是为管理收集建议。考虑到调查问题的意图和措辞,也许最有趣的是,在2014年,我们看到在统计上,关系冲突显著减少(占总回答的48%至36%),而物质冲突急剧增加(2007年为53%至2014年为74%)。乍一看,夏威夷小渔船渔业冲突的根源似乎很大程度上与物质问题有关。然而,当我们使用编码共现矩阵(表5)探索冲突的本质时,我们发现大部分冲突不仅是实质性问题,而且代表了关系的磨损(潜在的和/或基于身份的),这些关系使人们对其他利益相关者感到不那么信任,更有竞争力。正如其他人所指出的那样,关于实质内容的冲突通常是未解决的更深层次冲突的外在表现(Madden和McQuinn 2014, Crowley等人2017)。编码共现矩阵说明了哪些维度在关系和物质之间的相关度最高的地方同时发生,2007年的系数为0.510,2014年的系数为0.421(表5)。这些发现表明,夏威夷小渔船渔业中出现的物质问题可能确实深深植根于潜在的、基于身份的冲突中,物质问题可能作为未满足的社会需求的象征性表现而浮出水面。
将关系冲突不当地处理为表面层面的实质问题可能会导致短期的生物学收益,但随着时间的推移,冲突持续存在并重新出现,导致持续的辩论模式(Christie 2004, Pollnac et al. 2010)。例如,通过听取渔民关于调节特定装备(物质)的建议,而不是在关系维度内解决不信任和不尊重的感觉,它可能会引发加深攻击行为的补偿行为,恶化信任,并进一步巩固底层和身份层面的冲突(Reed 2008, Madden和McQuinn 2014)。
然而,人际关系不仅是冲突的原因,也是解决冲突的方法。无论是改善沟通、融洽关系,还是建立信任,加强夏威夷小渔船渔业内部和外部的关系,都是使问题更易于处理的关键。在这里,将冲突框架与自动化方法结合使用的价值在于能够以快速可靠的方式更完整地表示驱动程序和冲突处理。通过准确地区分真正的实质冲突和实质问题是更深层次关系冲突的象征性表现的冲突,我们可以提高长期成功的机会。识别和解决社会冲突的隐藏根源,可以将焦点从更深层次的冲突转移到争议层面,在争议层面,可以更大程度地确定可以作为协商分歧的社会基础的共识领域。
表示流程维度的代码较少,并且流程和其他冲突维度之间的共同出现率很低。然而,这并不意味着这一过程不重要,只是渔业参与者不太可能将其作为一项管理建议或需要进一步研究的主题。有效的决策过程可以提高管理决策的可接受性,并加强关系和建立信任(Madden and McQuinn 2014)。注意程序设计可能是改善与实质性争端更明显有关的紧张关系的另一种手段。
需要注意的是,这里提供的字典方法并非没有局限性。首先,基于字典的ACA仍然需要几个初始的主观步骤,并且在第一轮手动编码中引入的任何偏差都将应用于后续的自动化分析。仍然需要执行MCA来开发预定的类别列表以及将文本分配到相应类别的单词列表。在我们的例子中,所有的编码都是由一个研究人员进行的。虽然多名编码人员可以提高信心,但我们并没有让两个人对整个数据集进行编码,而是为了提高效率而依靠研究团队之间的讨论。多个编码员可以通过测量编码员之间的一致程度来帮助确保分类的一致性,但雇用第二个编码员是资源密集型的(MacPhail等人,2016年)。使用多个编码员需要测试编码员之间的可靠性,以评估这些编码员做出类似编码决策的程度(Lombard et al. 2010),对于较小的数据集,培训编码员的可靠性所需的时间可能会耗尽数据集。
另一个限制是渔业词典的高准确性只解释了第一类错误(假阳性),而不是第二类错误(假阴性)。第二类错误不包含已建立的关键字/短语,软件将不会检测到,精度可能会受到影响。第一类误差受到80%有效性规则迭代过程产生可靠结果的限制(Bengston和Xu 1995)。第二类错误,或被错误地忽略的响应,更难控制。如果应答者所说明的概念与字典中的关键字/短语不匹配,则该应答将在分析过程中被忽略。WordStat 8.0.16包含了管理第二类错误的工具,但它们是基本的。一种工具使研究人员能够分析字典覆盖数据集的统计数据,例如由字典自动编码的句子、段落和案例的百分比。词典覆盖率的下降可能表明出现了新的主题,方言发生了变化,或者是时候让词典适应新的数据了。
结论
NOAA 2007年和2014年的夏威夷小船渔业调查提供了有用的数据集,用于在渔业冲突背景下构建和测试基于字典的ACA方法。我们发现字典方法表现得很好,大多数术语的准确性可以与MCA相媲美。数据集的大小和性质是字典方法成功的关键,构建字典的方法也是如此。数据集足够小,可以手动编码和开发概念,但又足够大,可以收集重复的关键字和短语,为ACA构建字典。数据集描述了可预测的、常见的和一致的资源问题。使用MCA通知字典,而不是自动生成字典,确保字典忠实于单词的含义,并与冲突上下文相关。虽然开发该词典的前期投入很大,但它可以用于有效地分析夏威夷小渔船渔业调查的未来结果。这项研究展示了如何在渔业和自然资源保护科学领域应用基于字典的方法,为方法学工具箱提供了有价值的补充。
致谢
我们感谢所有参与调查的参与者和国家海洋大气管理局提供的数据获取和后勤支持。我们感谢Thomas Oliver博士的统计援助和太平洋岛屿渔业科学中心(PI: Dr. Minling Pan)的财政支持。NA11NMF4320128)。
数据可用性
支持本研究结果的数据/代码可在NMFS企业数据管理计划中公开获取https://www.fisheries.noaa.gov/inport/item/62698,参考号[62698]。
文献引用
安博斯特,2017年。内容分析中的主题接近性。SAGE Open, 7(2)。https://doi.org/10.1177/2158244017707797
阿斯哈尔,M. Z.汗,S.艾哈迈德,B.艾哈迈德,2013。面向药物综述挖掘的主体性词汇构建。科学国际26:145-149。
徐振民,徐德宁,彭志明,1995。变化中的国家森林价值:内容分析。研究论文NC-323。美国林务局,北中央森林实验站,明尼苏达州圣保罗。https://doi.org/10.2737/NC-RP-323
Bengtsson, M. 2016。如何使用内容分析计划和执行定性研究。NursingPlus Open 2:8-14。https://doi.org/10.1016/j.npls.2016.01.001
鲍曼斯,J. W.和D.特里林,2016。盘点工具包:为数字新闻学者提供的相关自动化内容分析方法和技术概述。数字新闻4:8-23。https://doi.org/10.1080/21670811.2015.1096598
卡瓦纳,1997。内容分析:概念、方法和应用。护士研究员4:5-16。https://doi.org/10.7748/nr.4.3.5.s2
陈海林,潘敏,2017。2014年夏威夷小船渔业的经济和社会特征。美国商务部、国家海洋和大气管理局、国家海洋渔业局、太平洋岛屿渔业科学中心,美国夏威夷檀香山。
查马兹,K. 2006。构建扎根理论:定性分析的实践指南。SAGE,洛杉矶,加州,美国。
克里斯蒂,2004年。海洋保护区:东南亚生物的成功与社会的失败。美国渔业学会研讨会42:155-164。
C.康纳利-埃亨,L. A.埃亨和D. S.博尔特里,2009。分层构造周抽样对电子新闻源档案内容分析的有效性:AP新闻专线、商业专线和美通社。新闻与大众传播季刊86:862-883。https://doi.org/10.1177/107769900908600409
克劳利,S. L.辛克利夫,R. A.麦克唐纳。2017.入侵物种管理中的冲突。生态环境前沿15:133-141。https://doi.org/10.1002/fee.1471
邓Q., M. Hine, S. Ji, S. Sur. 2017。为IT行业建立环境可持续性字典。第50届夏威夷系统科学国际会议记录950-959。https://doi.org/10.24251/HICSS.2017.112
邓Q., M. J.海因,季S.和S. Sur. 2019。文本分析词典构建的黑盒内部:一种设计科学方法。国际技术与信息管理杂志27:19 -159。
Elo, S, H. Kyngäs。2008.定性内容分析过程。高级护理杂志62:107-115。https://doi.org/10.1111/j.1365-2648.2007.04569.x
Erlingsson, C.和P. Brysiewicz. 2017。内容分析的实践指南。非洲急诊医学杂志7:93-99。https://doi.org/10.1016/j.afjem.2017.08.001
富尔顿,A. D. M.史密斯,D. C.史密斯和I. E.范普特,2010。人类行为:渔业管理中不确定性的主要来源。渔业12:2-17。https://doi.org/10.1111/j.1467-2979.2010.00371.x
格拉泽,B.和A.施特劳斯,1967。接地理论:接地理论的发现。社会学:英国社会学协会杂志12:27-49。
格林,H. 2014。在定性研究中使用理论和概念框架。护士研究员21:34-38。https://doi.org/10.7748/nr.21.6.34.e1252
格里默,J.和B. M.斯图尔特,2013。作为数据的文本:政治文本自动内容分析方法的前景与缺陷。政治分析21:267-297。https://doi.org/10.1093/pan/mps028
《医院》,J.、S. S.布鲁斯和M.潘,2011。夏威夷远洋渔船渔业的经济和社会特征。太平洋岛屿渔业科学中心,国家海洋渔业局,NOAA,檀香山,夏威夷,美国。
Kamhawi, R.和D. Weaver, 2003。1980 - 1999年大众传播研究趋势。《新闻与大众传播季刊》80:7-27。https://doi.org/10.1177/107769900308000102
梁静茹,k.m., A.托雷斯,S.怀斯,2020。超越娱乐:钓鱼的动机不仅仅是运动或娱乐。国家海洋和大气管理局,华盛顿特区,美国。
朗巴德,M.斯奈德-杜赫,C. C.布莱肯,2010。内容分析研究项目中评估和报告编码器可靠性的实用资源。(在线)网址:http://matthewlombard.com/reliability/index_print.html
Luke, D. A. Caburnay, E. L. Cohen, 2011。多少才够?在报纸健康报道内容分析中使用构造周抽样的新建议。通讯方法与措施5:76-91。https://doi.org/10.1080/19312458.2010.547823
麦克菲尔,C., N. Khoza, L. Abler, M. Ranganathan, 2016。定性研究中建立编码器间可靠性的过程指南。定性研究16:198-212。https://doi.org/10.1177/1468794115577012
马登,F.和B.麦奎因。2014.保护的盲点:野生动物保护中的冲突转化案例。生物保护178:97-106。https://doi.org/10.1016/j.biocon.2014.07.015
迈尔,D., A.瓦尔德赫尔,P.米尔特纳,G.魏德曼,A.尼克勒,A.凯纳特,B.普菲奇,G.海耶,U.雷伯,T. Häussler, H.施密德-佩特里,S.亚当。2018。LDA主题建模在传播学研究中的应用:寻求一种有效可靠的方法。通信方法和措施12:93-118。https://doi.org/10.1080/19312458.2018.1430754
默希德-e-贾汉,K., B.贝尔顿,K. K.维斯瓦纳坦,2014。管理孟加拉国沿海渔业冲突的传播战略。海洋与海岸管理92:65-73。https://doi.org/10.1016/j.ocecoaman.2014.01.003
太平洋岛屿渔业科学中心。2021.夏威夷小渔船渔业的自动化内容分析。美国夏威夷檀香山太平洋岛屿渔业科学中心。(在线)网址:https://www.fisheries.noaa.gov/inport/item/62698
波纳克,R., P.克里斯蒂,J. E.辛纳,T.道尔顿,T. M.道,G. E.福里斯特,N. A.格雷厄姆和T. R.麦克拉纳汉。2010.海洋保护区是相互联系的社会-生态系统。美国国家科学院学报107:18262-18265。https://doi.org/10.1073/pnas.0908266107
波默罗伊,R., J.帕克斯,R. Pollnac, T. Campson, E. Genio, C. Marlessy, E. Holle, M. Pido, A. Nissapa, S. Boromthanarat和N. T. Hue, 2007。鱼战:东南亚渔业管理中的冲突与合作。海事政策31:645-656。https://doi.org/10.1016/j.marpol.2007.03.012
里德,m.s., 2008。环境管理中的利益相关者参与:文献综述。生物保护141:2417-2431。https://doi.org/10.1016/j.biocon.2008.07.014
罗布森,M.和T.戴维斯,2014。根据1994年至2009年安大略省《皇家森林可持续发展法》和森林管理规划手册,评估向可持续森林管理的过渡。加拿大森林研究杂志45:436-443。https://doi.org/10.1139/cjfr-2014-0269
斯皮克斯,J., T. H.莫里森,R.布拉西亚克,G. S.卡明,M.奥斯本,J.沃森和H. Österblom。2018.海洋渔业和未来的海洋冲突。渔业19:798-806。https://doi.org/10.1111/faf.12291
斯蒂芬科娃,S. A. P.基里连科,A. M.莫里森,2009。促进旅游研究的内容分析。旅行研究杂志47:454-469。https://doi.org/10.1177/0047287508326509
特里林,D., J. G.琼克曼,2018。扩大内容分析。通信方法和措施12:58 -174。https://doi.org/10.1080/19312458.2018.1447655
杨,L.和S.索拉卡,2012。情感新闻:政治文本中情感的自动编码。政治沟通29:205-231。https://doi.org/10.1080/10584609.2012.671234